En arkitektur på vranga
For å kunne starte denne serien, måtte jeg først skrive om rene funksjoner og uforanderlige data. Faktisk viste det seg å være tvingende nødvendig. “Funksjonell kjerne, imperativt skall”-arkitekturen (FK/IS) har nemlig som hovedmål å maksimere effekten av disse to bestevennene. Den lenkede bloggposten svarer altså på hvorfor-spørsmålet i større grad enn denne vil gjøre. Nå blir det mer “hvordan henger det sammen” - og senere bloggposter vil gå mer inn på “hvordan får vi det til”.
Den klassiske trelagskaka
Hvis du har jobbet i IT-bransjen en stund så er det overhengende fare for at du har jobbet på et prosjekt med denne klassiske trelags-arkitekturen:
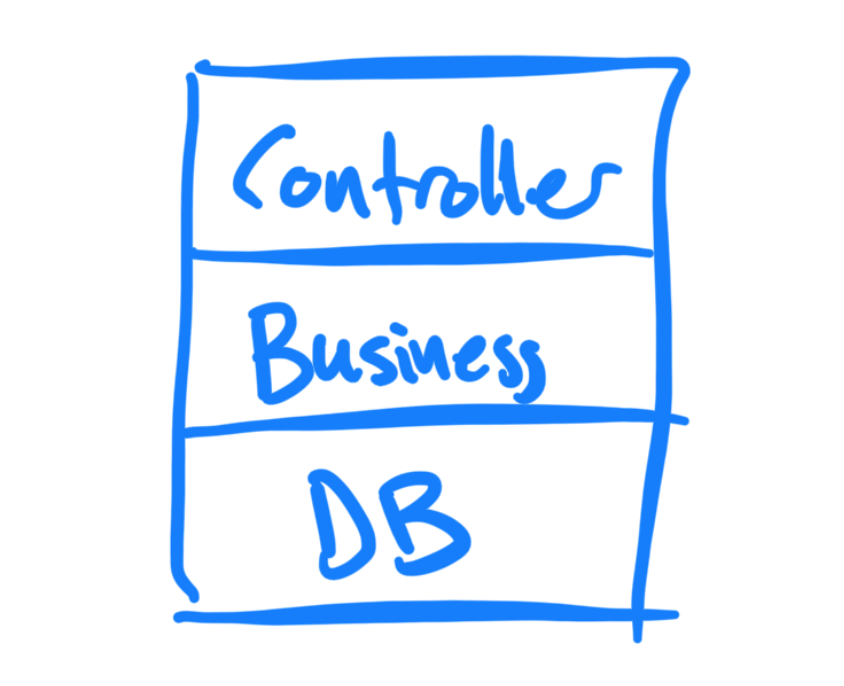
Som oftest kommer det HTTP-forespørsler inn på toppen, kanskje det er noen REST-endepunkter, som så delegerer videre ned til et slags domene/business-lag, som igjen hviler på et dataaksess-lag. Sistnevnte kan være Active Record, Hibernate, eller noen egendefinerte Repositories.
Det de har til felles er at hele kaka hviler på et fundament av databasen. En database - vel å merke - som er i konstant bevegelse.
FK/IS røsker databasen ut og dytter den til siden:
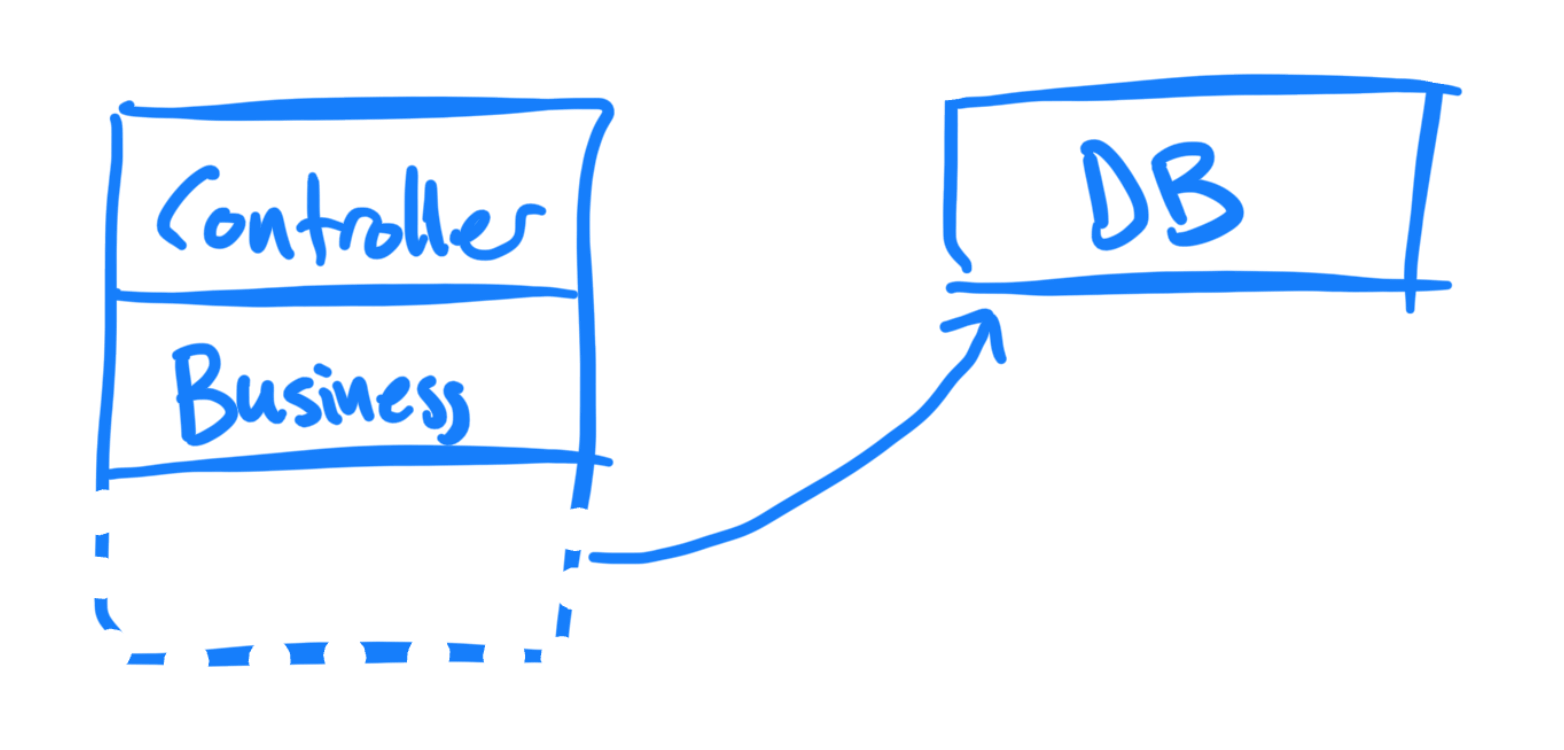
Den funksjonelle kjernen har samme funksjon som business-laget, mens det imperative skallet fungerer som controlleren:
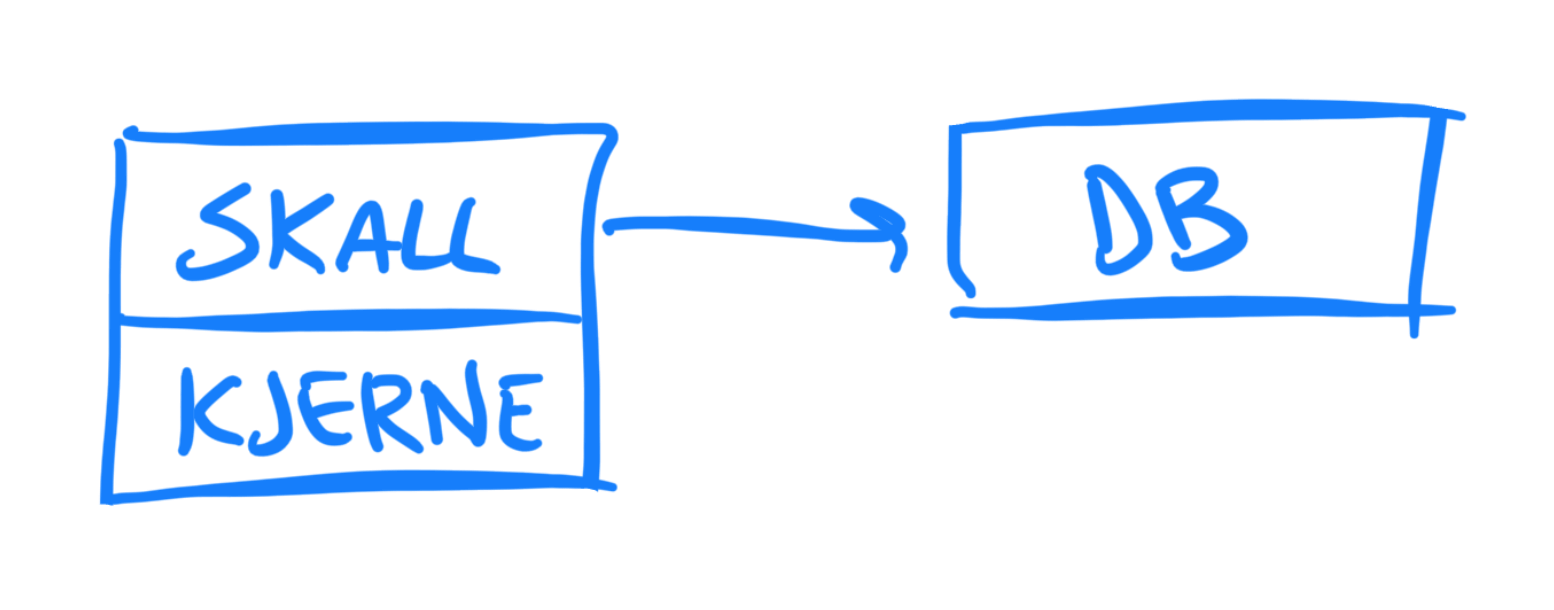
Den store forskjellen er at den funksjonelle kjernen ikke har noe kjennskap til databasen eller andre levende prosesser - den består kun av rene funksjoner og uforanderlige data. Det imperative skallet håndterer “alle de greiene der” - slikt som å snakke med databasen.
Så hvordan fungerer det her egentlig? Hvordan kan business-laget få gjort noe som helst hvis det ikke kan lese fra eller skrive til databasen?
Analogien
Tenk på den funksjonelle kjernen som presidenten og hennes stab. De sitter på et rom og blir forelagt all relevant informasjon om en sak, så drøfter de seg i mellom, før det blir tatt en avgjørelse om hva som skal gjøres.
Merk: Presidenten tar avgjørelsen, men hun gjennomfører ikke arbeidet selv.
Istedet produseres et dokument, en ordre, en plan. Denne blir tatt med ut av rommet og gitt til dem som skal gjennomføre.
På akkurat samme måte blir den funksjonelle kjernen forelagt all relevant informasjon, tar en avgjørelse om hva som skal gjøres, og svarer tilbake med en plan. Deretter er det det imperative skallet som utfører arbeidet.
Eksempel
For å gjøre det mer konkret, her er et utdrag fra vår kodebase. Vi får inn en forespørsel med en kommando fra en bruker:
{:command/kind :commands/planlegg-tur
:command/data {:serveringssted/id "abc"
:tur/filtere {:filter/kveldsinspeksjon :uten}}
:command/mastermind [:bruker/id "oms"]}
Her planlegger brukeren "oms" en tur til serveringsstedet "abc", og vil
gjerne filtrere bort steder som krever kveldsinspeksjon.
Denne kommandoen blir sendt inn til kjernen – sammen med annen relevant informasjon – som svarer med denne datastrukturen:
{:plan/effects
[{:effect/kind :db/transact
:effect/data
[{:tur/deltakere #{{:deltaker/rolle :deltaker.rolle/inspektør
:deltaker/person [:bruker/id "oms"]}}
:tur/status :tur.status/planlegges
:tur/filtere {:filter/kveldsinspeksjon :uten
:filter/omkrets 50.0}
:tur/stoppene #{{:stopp/serveringssted {:serveringssted/id "abc"}}}}]}]}
Her ser vi en plan, og effektene den vil ha gjennomført. Det skal transactes’ en
tur inn i databasen, med "oms" satt som deltaker på turen, og "abc" som
første stopp. Merk at kjernen har beriket med en inspektør-rolle til deltakeren,
lagt til en planlegges-status på turen, og satt et omkrets-filter.
Omkrets-filteret er interessant, fordi det bestemmer utsnittet av kartet som brukes til å finne andre relevante steder i nærheten å dra til, og vil være større eller mindre avhengig av hvor langt man må belage seg på å reise for å finne flere serveringssteder å besøke. Det er altså gjort et omfattende arbeid i kjernen.
Slik kommuniserer kjernen sine effekter uten å gjennomføre dem. Ikke bare er dette veldig lett å teste (ingen stubs eller mocks nødvendig) – det er også helt trygt å kjøre koden i repl-et. Ingen side-effekter skjer uten at man har kontroll.
Til slutt - og videre
Målet med denne arkitekturen er å maksimere mengden rene funksjoner og uforanderlige data. Fordi det er så utrolig fett å jobbe med. Så hva er resultatet? Fikk vi det vi ville?
I kodebasen vi jobber med nå (Matnyttig, for de som følger ekstra godt med) har vi for øyeblikket 21 000 linjer med kode. Av disse er 18 000 i den funksjonelle kjernen. Bare 15% av koden er i skallet - alt annet er kun rene funksjoner.
Det er nok usedvanlig gode tall - vi har tatt mange grep for å komme oss dit. Og det er nettopp det denne serien kommer til å handle om videre: Hvordan fikk vi til det her?
