Når det går litt fort i svingen
Jo, da blir svingen bred. Vi fant nylig ut at svingen vi tok i geo-søkene våre kunne bli noen mil bredere enn strengt tatt nødvendig. Snakk om omvei.
Hvis du vet hvor du skal, hvorfor lete i hele landet?
Etter en teknisk endring, som gjorde at spørringer for å oppdatere klientene ble kjørt ved hver eneste transaksjon, så vi hyppige innslag av store spørringer som tok lang tid og slo opp veldig mange ting.
Hvorfor henter vi 20 000 entiteter fra databasen og filtrerer dem i koden etterpå? Når det logges info om hver av disse for flere brukere for hver transaksjon mot basen, blir det litt data å lagre. Disse sjekkene kunne ta opptil fire sekunder hver. Så hvilken spørring var dette?
Jo, vi må jo finne serveringssteder i nærheten av de stedene inspektørene planlegger å besøke, men hadde ikke vi noe filtrering på plassering? Vi tenkte at det var greit å debugge lokalt, så da tok vi en titt på en av turene Ole Marius planla i sitt utviklingsmiljø. Denne tok sin tid, og filtrerte først serveringssteder på omtrent 18 000 geohasher. Turen skulle besøke noen restauranter i Oslo og en i Moss, så da lette vi like gjerne fra midten av Vestfold i sørvest til Kongsvinger i nordøst i en samling ved å filtrere på en hel haug med små firkanter.
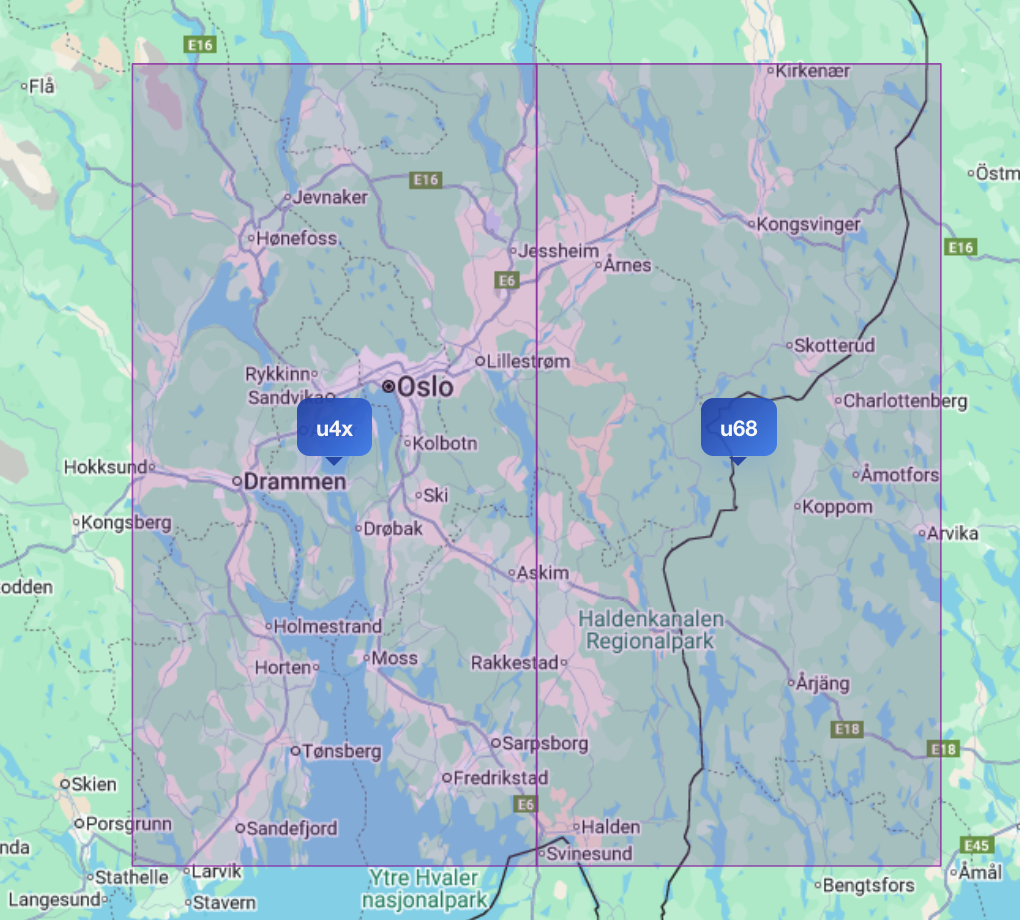 Her ser du det omtrentlige
utsnittet vi søkte i, bare at vi brukte rundt 18 000 bokser istedenfor 2.
Her ser du det omtrentlige
utsnittet vi søkte i, bare at vi brukte rundt 18 000 bokser istedenfor 2.
Ikke nok med det, vi fant ut at vi brukte starts-with?. Dokumentasjonen til
Datomic sier at du ikke skal bruke det fordi da brukes ikke indekser til å søke
med.
Så da skannet vi gjennom alle serveringssteder i databasen, traff en hel haug av
dem, så filtrerte vi dem på avstand en gang til etterpå.
Voffor gör vi på detta viset?
Det hadde riktignok skjedd en endring en gang i tiden. Vi pleide å bare se i nærheten av ett enkelt sted, men så begynte vi med turer og tenkte at det var lurt å se på områdene mellom serveringsstedene også. Hva er en lur måte å gjøre det på, mon tro? Vi begynner i midten og lar utsnittet vokse utover til alle stedene i turen er med. Dette funker fint når det ikke er så langt mellom stedene som allerede er i turen, men etter som du legger til steder, kan dette utsnittet vokse voldsomt. Særlig om du bytter søkeradius fra for eksempel 5 mil til 200 meter som gjør størrelsen på boksene vi ser på mye mindre. Det siste filteret vårt kastet uansett alle treffene som lå på strekningen imellom, så vi hadde ingen glede av det.
Da hadde vi to klare optimeringer vi kunne gjennomføre:
- Let bare i nærheten av stedene og ikke overalt ellers
- Bruk
>=og<for å utnytte indeksene i basen
Den første er nesten triviell, selv om det tok litt tid å få alt helt riktig. Vi kan hente ut en liten “ring” med geohasher rundt hvert serveringssted og kaste duplikater.
Leksikalsk sammenlikning av geohasher
Geohasher er tallstrenger med 32 som grunntall. Antall siffer bestemmer
nøyaktigheten, eller størrelsen på området, til geohashen. Så min første tanke
var å bruke Javas Long.valueOf(String s, int radix) med 32 som grunntall for å
tolke geohashen, men det var noe rart med disse geohashene. Det høyeste sifferet
Z er siste bokstav i det latinske/engelske alfabetet som har 26 bokstaver. Med
mindre det har skjedd noe rart med matematikk siden jeg gikk på skolen, så er
ikke 26 + 10 = 32.
Niemeyer var en liten luring da han fant på geohasher, og fjernet noen av bokstavene fra det engelske alfabetet, men ikke fra slutten. Heldigvis tullet han ikke rundt med rekkefølgen av bokstavene. Vi vil bare at dette skal fungere med indeksene til Datomic, og de bruker leksikalsk sortering av strenger. Så vi kan bare bruke grunntallet 36 isteden. Da kan vi lett få en øvre grenseverdi ved å inkrementere og konvertere til en streng igjen:
(defn geohash-spenn [geohash]
[geohash (-> (Long/parseLong geohash 36)
inc
(Long/toString 36))])
Resultatet av funksjonen over er en tuppel med en nedre og øvre grense for
geohasher med prefikset geohash. Alle serveringsstedene har posisjoner med høy
nøyaktighet og flere siffer enn disse prefiksene når vi søker etter treff i litt
større områder. Så da kan vi bruke indeksene med >= for den nedre grensen og
< for den kunstige øvre grensen vi har lagd:
(defn finn-adresser-med-geohash
"Finner adresser som er (eller har vært) i bruk av serveringssteder og som
har en av de angitte geohash-ene."
[app-db matrikkel-db geohash-er]
(d/q '[:find [?a ...]
:in $ [[?hash ?end] ...]
:where
[?a :matrikkel.adresse/id ?mid]
[?a :posisjon/geohash ?gh]
[(>= ?gh ?hash)]
[(< ?gh ?end)]]
db
(mapv geohash-spenn geohash-er)))
Da vi prøvde dette, var vi litt usikre på om vi kunne bruke
samling-av-tupler-notasjonen, [[?hash ?end] ...], i spørringen, men det
håndterte Datomic helt fint.
Ble det raskt, da?
Alt er relativt. I eksempelturen fra Oslo til Moss, gikk det fra rundt 4 sekunder til et halvt sekund. Så fikk vi antallet entiteter vi slo opp ned fra rundt 20 000 til omtrent 4000. Vi ser fortsatt ting som tar tid, særlig når størsteparten av Oslo ender opp i søket fordi man bruker en stor søkeradius, og særlig om adressene i området ikke er i cache, men da er det naturlig at det tar litt tid.
Hva annet kan vi gjøre for å forbedre dette? Når det kommer til diskbruken med disse store mengdene innslag per entitet som slåes opp, kan vi samle disse i én gruppe. Vi kan forbedre utvalget geohasher vi søker i enda mer ved å bruke litt tyngre beregninger på hvilke som inngår i en bestemt radius rundt et punkt. Vi har også noen kandidater til å filtrere bort resultater i spørringen istedenfor å grave i entitetene etterpå. Så er det nok interessant å ikke utføre disse søkene for hver eneste transaksjon. Det siste er Magnar allerede i gang å jobbe med.
