Datomic, hvorfor er spørringen min treig?
Nå i januar var vi en gjeng på fire som ble med i Team Servering, en tjenestedesigner og tre utviklere. Ole Marius og jeg har brukt noe av tiden til å se litt på ytelsesproblemer. Vi fikk se hvordan noen av sidene tok litt vel laaang tid å laste, og en introduksjon til sporingen som var satt opp med OpenTelemetry.
Treige spørringer
En av tingene vi fant i sporene var spørringer som tok lengre tid enn vi hadde
forventet. Ole Marius hadde sett et foredrag fra Clojure Conj
2023 om
query-stats og io-stats i Datomic som gir oss informasjon om kjøringen av
spørringer. Vi kan be Datomic gi oss denne informasjonen ved å sette et flagg
for :query-stats og angi en :io-context:
(require '[datomic.api :as d])
;; Dette er en veldig tullete spørring
(d/query {:query '[:find [?e ...]
:where [?e :db/ident]]
:args [my-db]
:query-stats true
:io-context :my/io-context})
Istedenfor å få resultatet direkte, får vi nå ut en map der resultatet av
spørringen ligger på :ret. I tillegg får man også :query-stats og
:io-stats:
{:ret
[17592186045420
...],
:io-stats
{:io-context :my/io-context,
:api :query,
:api-ms 11.69,
:reads {:aevt 1, :ocache 1}},
:query-stats
{:query [:find [?e ...] :where [?e :db/ident]],
:phases
[{:sched (([?e :db/ident])),
:clauses
[{:clause [?e :db/ident],
:rows-in 0,
:rows-out 255,
:binds-in (),
:binds-out [?e],
:expansion 255,
:warnings {:unbound-vars #{?e}}}]}]}}
Io-stats gir oss informasjon om hvor data leses fra og skrives til, på indeks- og cache-nivå, og hvor lang tid spørringen tok. Query-stats gir oss noe som likner en spørreplan, som du kanskje kjenner fra relasjonsdatabaser. Den viser hvordan datomic har delt opp spørringen i faser, og hvordan oppslag er gjort per clause, eller ledd.
Den enkle spørringen over har bare ett ledd, entitene vi skal ha ut må ha en
:db/ident, som er påkrevd for alle skjema-entiteter. Det vi kan se over er at
ingen tidligere ledd har gitt noen rader inn til dette leddet, :rows-in,
og dette leddet plukket ut 255 entiteter, :rows-out. Forskjellen mellom disse
finner vi i :expansion Vi kan også se at ingen variabler hadde blitt bundet i
et tidligere ledd, :binds-in, men dette leddet har bundet opp ?e til disse
255 entitene. Når :binds-in er tom, får man en advarsel om :unbound-vars.
Dette kan være et problem, men er ikke alltid mulig å unngå.
Så hva ser vi etter?
Det typiske problemet med en Datomic-spørring er at et ledd plukker ut en hel haug med data hvor man bare er interessert i et lite utsnitt. Da vil man typisk ha et ledd som har veldig mange rader ut, og et senere ledd som har ganske få rader ut. Dette var akkurat det vi så da vi kjørte noen av disse spørringene:
{...
:query-stats
{:phases
[{...
:clauses
[...
{:clause [?tl :tilsynsløp/saksår ?saksår],
:rows-in 48,
:rows-out 258528,
:binds-in [?saksår ?serveringssted],
:binds-out [?serveringssted ?tl],
:expansion 258480}
{:clause [?tl :tilsynsløp/serveringssted ?serveringssted],
:rows-in 258528,
:rows-out 17,
:binds-in [?serveringssted ?tl],
:binds-out [?serveringssted ?tl]}
...]}]}}
Oi, se der, ja. Der hentet vi visst opp 258 528 rader som vi like etter snevret inn til bare 17 rader. Så la oss se hva som skjer når vi snur på rekkefølgen av disse to leddene:
{...
:query-stats
{:phases
[{...
:clauses
[...
{:clause [?tl :tilsynsløp/serveringssted ?serveringssted],
:rows-in 48,
:rows-out 229,
:binds-in [?saksår ?serveringssted ?tl],
:binds-out [?serveringssted ?tl]
:expansion 181}
{:clause [?tl :tilsynsløp/saksår ?saksår],
:rows-in 229,
:rows-out 17,
:binds-in [?saksår ?serveringssted ?tl],
:binds-out [?serveringssted ?tl]}
...]}]}}
Det ble jo hakket bedre med 229 rader som den “store ekspansjonen”. Kjøretiden til denne spørringen tar nå under 10% av hva den gjorde før. Ganske snasent, egentlig.
Hvis du ikke har brukt Datomic, lurer du kanskje på om det finnes noe
tilsvarende i relasjonsdatabaser? Og ja, det gjør det så absolutt. Dette
tilsvarer problemet du får når kolonnene i en indeks ligger i feil rekkefølge.
Dette er ikke nødvendigvis like lett å se når du bruker en EXPLAIN PLAN som
det var her med Datomics query-stats, men det blir det tilsvarende verktøyet.
Kjekt å ha
Det hadde jo vært fint om man ikke trengte å manuelt teste hver eneste spørring i et REPL, selv om det er fint at det går an. Vi har jo en masse fin sporing i OpenTelemetry allerede. Da hadde det jo vært fint å ha dette med der, men vi vil ikke at dette skal påvirke ytelsen i produksjon. Så dette kan slåes av eller på for applikasjonen i sin helhet i konfigurasjonen, og dette er på i utvikling. Man kan også bruke en annen funksjon i en liten wrapper vi har foran Datomic, for å få denne sporingen på én enkelt spørring.
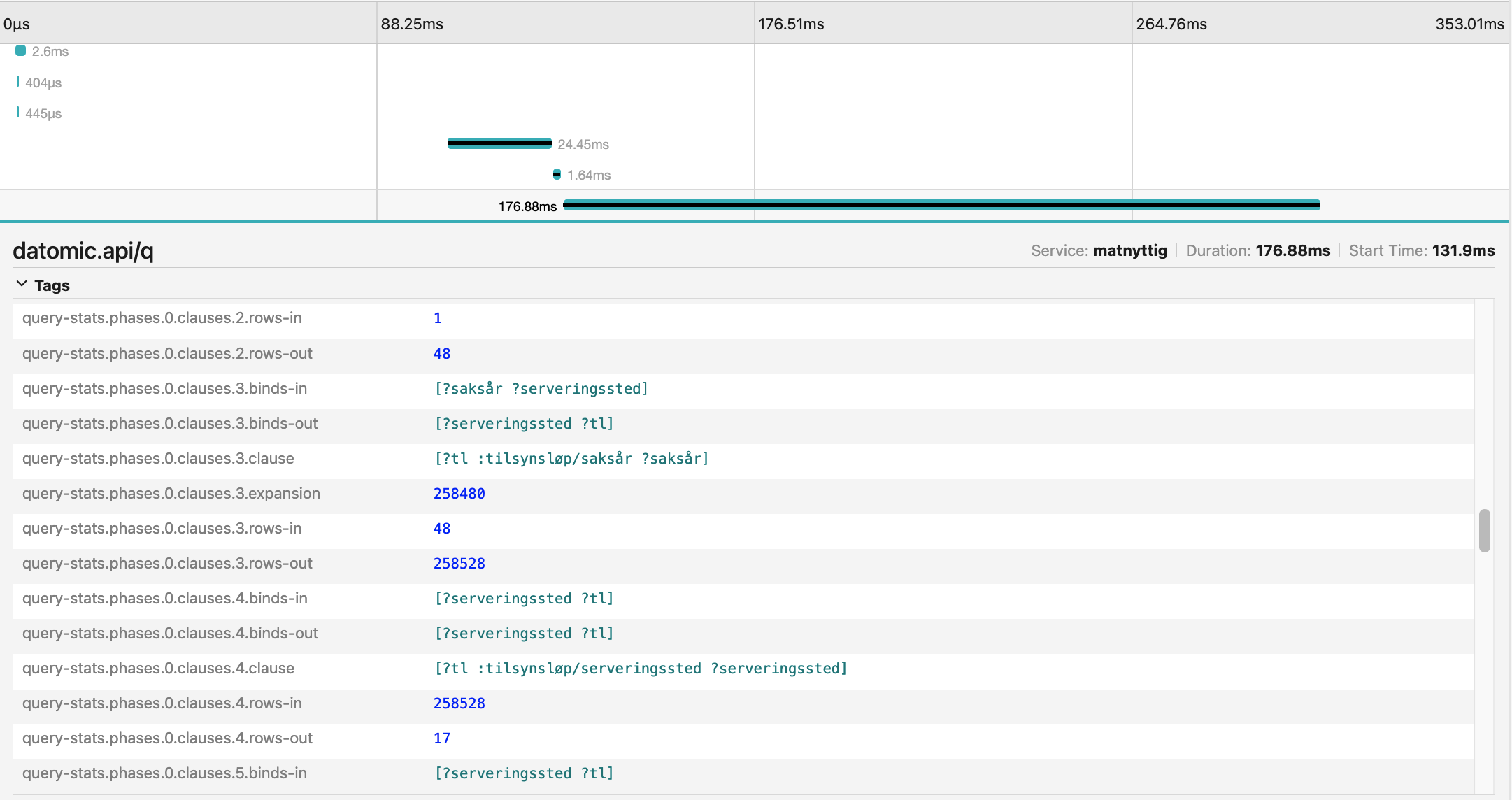
Her ser vi sporet etter den samme spørringen på nytt i verktøyet Jaeger som vi bruker i utvikling til å se på OpenTelemetry-sporene våre. Legg merke til at kjøretiden er på 177 ms, og under tags finner vi query-stats med de samme dataene som vist ovenfor.
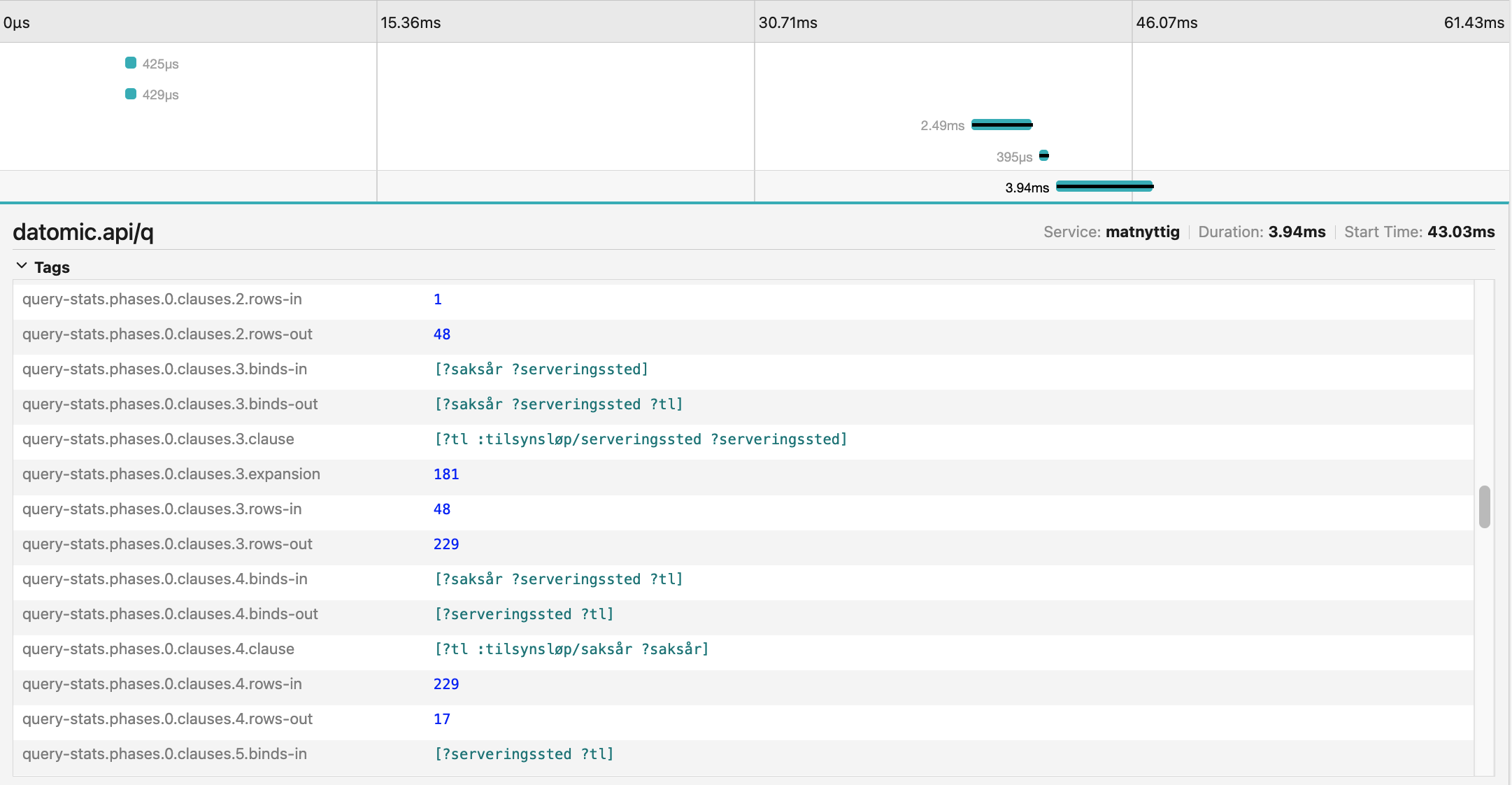
Og her er sporet etter optimeringsarbeidet på denne var gjort. Her kan du se at kjøretiden nå er på rundt 4 ms. Hvis du ser nøye etter, kan du se noen spor av at andre deler av denne siden ble optimert i det samme arbeidet.
Siden det allerede var lagd et lite stillas rundt OpenTelemetry, og Datomic eksponerte disse dataene på en så enkel måte, var det overraskende lett å få dyttet denne informasjonen inn i sporingen vår. Det hadde vært gøy å se hva som må til for å få til noe liknende med en SQL-base.
